

Anouschka W. | 14.02.2023
Zurück zur Übersicht
Von: Anouschka W. - 02.10.2024

Maschinelles Lernen ist heute in vielen Bereichen im Einsatz, zum Beispiel in der Industrie oder im Gesundheitswesen. ML-Modelle unterstützen dabei Prozesse zu optimieren oder Probleme frühzeitig zu erkennen. Gleichzeitig verstehen meist nur Experten wie zuverlässig diese Systeme wirklich arbeiten. Da sich Daten und Rahmenbedingungen im laufenden Betrieb ändern können, ist ein kontinuierliches Monitoring notwendig. Das ist durch den Mangel an ML-Fachkräften oft schwierig. Umso wichtiger ist die Frage, wie Monitoring-Tools gestaltet sein müssen, damit auch Personen ohne ML-Expertise Veränderungen erkennen und sinnvoll darauf reagieren können.
Ein Machine-Learning-Modell lernt aus vergangenen Daten, um Vorhersagen für die Zukunft zu treffen. Solange sich die Daten aus der realen Welt nicht stark verändern, funktioniert das zuverlässig. Ändern sich jedoch Rahmenbedingungen, Nutzerverhalten oder äußere Einflüsse, passen die ursprünglichen Annahmen des Modells nicht mehr und die Vorhersagen werden ungenauer. Da sich die reale Welt ständig weiterentwickelt, müssen auch ML-Modelle regelmäßig überprüft und angepasst werden. Solche Veränderungen nennt man Drift. Ein bekanntes Beispiel sind Modelle, die vor der Corona-Pandemie trainiert wurden und plötzlich nicht mehr valide Ergebnisse liefern konnten.
Von Data Drift spricht man, wenn sich die Daten im laufenden Betrieb von den ursprünglichen Trainingsdaten unterscheiden. Das kann schleichend, saisonal oder sehr plötzlich passieren, etwa durch verändertes Nutzerverhalten oder externe Ereignisse. Ein bekanntes Beispiel ist der Lieferdienst Instacart: Während der Corona-Pandemie änderte sich das Kaufverhalten so stark, dass die Genauigkeit des Modells zur Prognose der Warenverfügbarkeit deutlich sank.
Um mithilfe des Design-Thinking-Ansatzes ein verständliches Monitoring-Tool für Personen ohne ML-Expertise zu entwickeln, wird ein reales Anwendungsszenario herangezogen. Dadurch kann der Prototyp gezielt auf die Bedürfnisse einer konkreten Zielgruppe zugeschnitten und anschließend in User-Tests überprüft werden.
Als Beispiel dient die Qualitätssicherung in der Gastronomie. Hier müssen Unternehmen sicherstellen, dass Lebensmittel gesundheitlich unbedenklich sind und gesetzlichen Vorgaben entsprechen. Ein zentrales Kriterium ist die Qualität von Frittieröl, das regelmäßig gemessen werden muss. Überschreitet der sogenannte TPM-Wert einen festgelegten Grenzwert, muss das Öl ausgetauscht werden. Machine Learning kann dabei unterstützen, den optimalen Zeitpunkt vorherzusagen und so Qualität und Wirtschaftlichkeit zu verbessern.
In Interviews mit Mitarbeitenden aus Fast-Food-Filialen wurde untersucht, wer ein berechtigtes Interesse am Monitoring von ML-Modellen hat und welche Bedürfnisse bestehen. Die Ergebnisse zeigen, dass einfache Möglichkeiten zur eigenständigen Überwachung und Wartung der Modellen eventuell die Fachkräfte entlasten könnten. Die Selbstsicherheit ein Modell ohne Expertise zu überwachen besteht aber nur dann, wenn das Verhalten des Modells nachvollziehbar ist und Handlungsmöglichkeiten klar aufgezeigt werden.
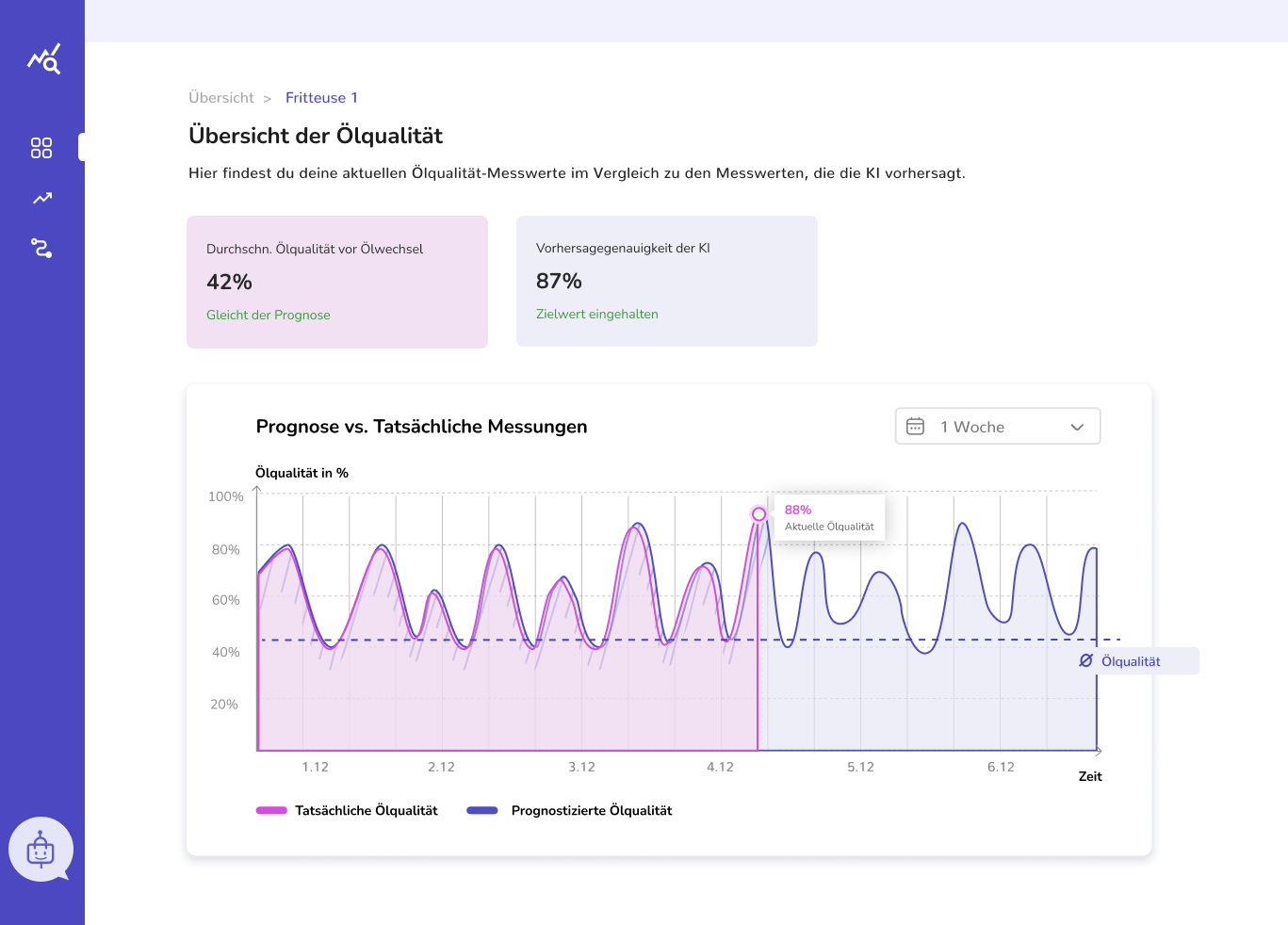
Auf Basis der Interviews wurde ein High-Fidelity-Prototyp entwickelt. Dieser bietet eine Übersicht über aktuelle Messwerte und Prognosen, zeigt Abweichungen visuell in Diagrammen und ergänzt diese durch kurze textliche Hinweise. Treten größere Abweichungen auf, wird dies klar hervorgehoben und erklärt.

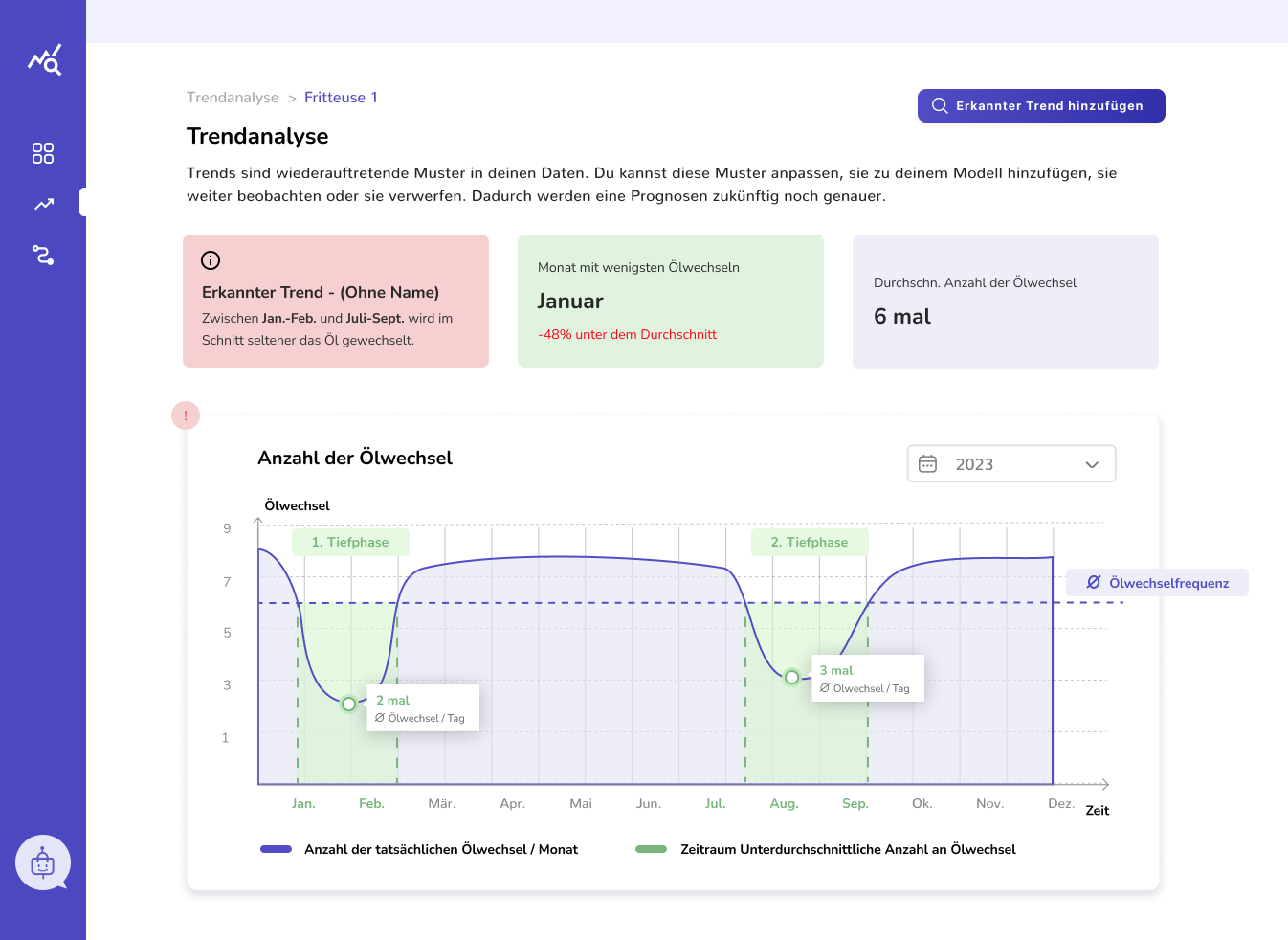
Ergänzend enthält der Prototyp eine Trendübersicht, in der wiederkehrende Abweichungen erkannt und eingeordnet werden können, sowie eine Ansicht zur Verwaltung verschiedener Modellversionen. Ein integrierter Chatbot unterstützt bei Verständnisfragen zu Diagrammen, Begriffen oder möglichen nächsten Schritten.
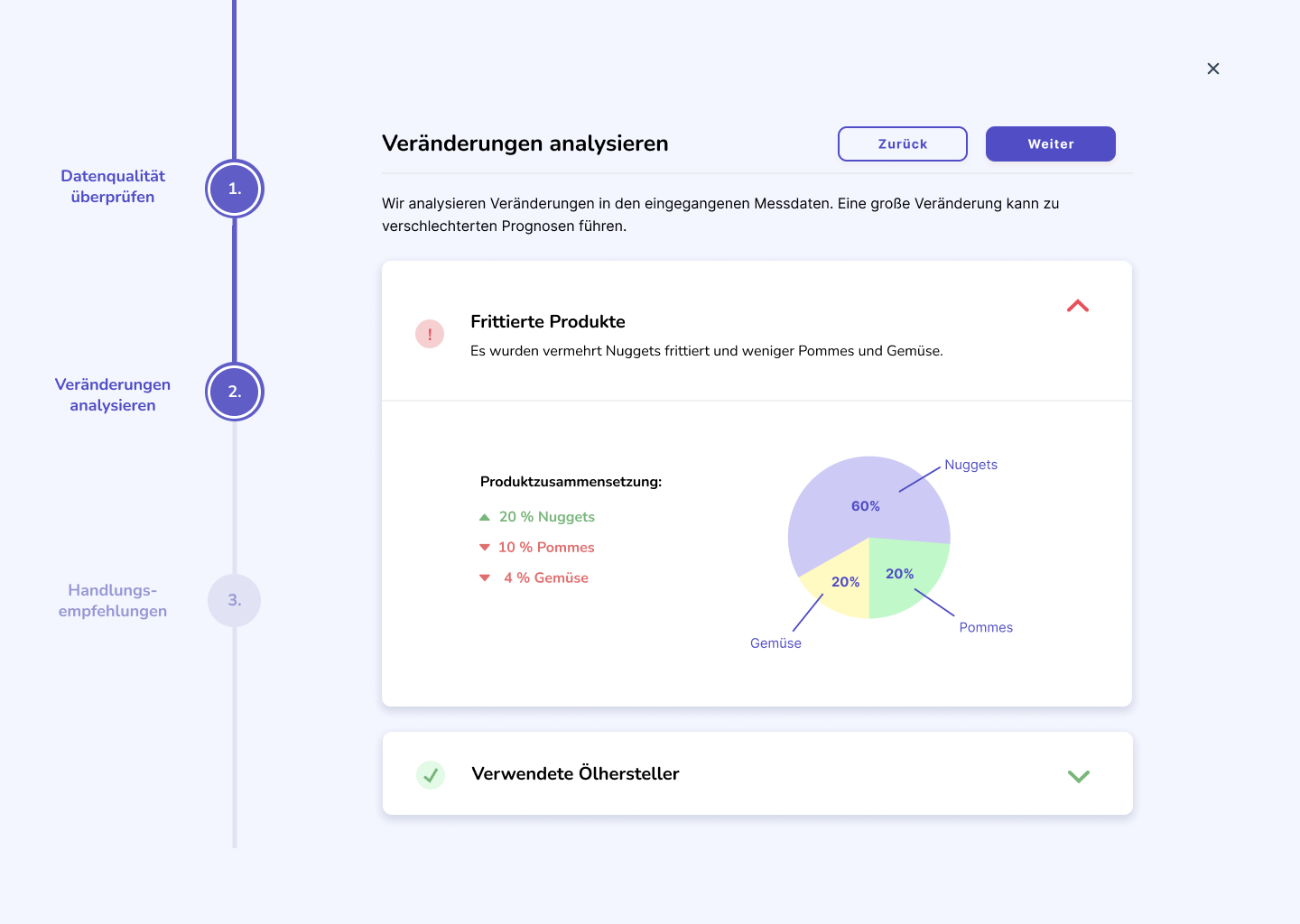
Zur Ursachenanalyse führt ein schrittweiser Wizard durch mögliche Gründe für erkannte Abweichungen. Nutzer können bekannte Ursachen auswählen oder neue hinzufügen, etwa saisonale Effekte oder einmalige Ereignisse. Diese Informationen können für zukünftige Modellanpassungen berücksichtigt werden.
Auf Basis der Ursachen werden passende Handlungsmöglichkeiten vorgeschlagen, zum Beispiel Schulungen bei fehlerhafter Nutzung. Als letzte Option steht ein einfaches Retraining zur Verfügung, das über einen geführten Prozess angestoßen werden kann. Dabei wird transparent dargestellt, ob sich die Modellgenauigkeit verbessert hat.
Abschließend wurde der Prototyp mit Personen unterschiedlicher ML-Erfahrung getestet. Ziel war es zu prüfen, ob Nutzer Drifts erkennen, Ursachen verstehen, geeignete Maßnahmen auswählen und diese selbstständig umsetzen können. Die Tests wurden mithilfe der Think-Aloud-Methode durchgeführt und durch kurze Bewertungen ergänzt, um die Verständlichkeit und Nutzbarkeit des Systems zu bewerten.
Die Nutzungstests haben gezeigt, dass ML-Monitoring für Nicht-Experten vor allem dann funktioniert, wenn es klar, handlungsorientiert und alltagsnah gestaltet ist. Statt technischer Details stehen schnelle Orientierung und konkrete nächste Schritte im Fokus.
Nutzer wollen vor allem wissen, was zu tun ist, wenn etwas nicht stimmt. Deshalb sollten mögliche Ursachen für Abweichungen bereits im Vorfeld mit passenden Handlungsempfehlungen verknüpft werden. Ein einfaches Ursache-Lösungs-Prinzip hilft, Probleme schnell zu erkennen und gezielt zu beheben.
Onboardings, kurze Erklärungen, Schritt-für-Schritt-Anleitungen oder ein Chatbot unterstützen dabei, das Tool auch unter Zeitdruck zu verstehen. Wichtig ist, dass Hilfe jederzeit verfügbar ist, ohne lange suchen zu müssen.
Zu viele Details überfordern. Stattdessen sollten nur die wichtigsten Informationen angezeigt werden, mit der Möglichkeit, bei Bedarf tiefer einzusteigen. Rollenkonzepte können helfen, Inhalte an unterschiedliche Nutzergruppen anzupassen.
Technische Begriffe wie „Retraining“ oder „Metriken“ sollten vermieden oder verständlich erklärt werden. Klare Überschriften und kurze Texte helfen Nutzer, Situationen richtig einzuordnen und Entscheidungen zu treffen.
Nutzer möchten verstehen, warum sich ein Modell anders verhält. Eine übersichtliche Darstellung relevanter Einflussfaktoren schafft Vertrauen und macht Zusammenhänge nachvollziehbar.
Besonders wichtig ist der sichtbare Nutzen im Alltag. Kennzahlen wie eingesparte Kosten oder reduzierte Aufwände zeigen, dass der Einsatz von ML einen echten Mehrwert bietet und nicht zusätzliche Arbeit verursacht.
Spielerische oder visuelle Elemente können helfen, komplexe Zusammenhänge verständlicher zu machen. Auch Animationen unterstützen dabei, Veränderungen zwischen Soll- und Ist-Zustand schneller zu erfassen.
Gutes ML-Monitoring für Nicht-Experten bedeutet nicht mehr Informationen, sondern die richtigen zur richtigen Zeit. Klare Erklärungen, konkrete Handlungsempfehlungen und ein starker Bezug zum Alltag machen den Unterschied. Die gewonnenen Erkenntnisse bilden eine erste Grundlage. Da dies nur ein erster Ansatz ist müssten weitere Iterationen folgen.
ML-Monitoring funktioniert für Nicht-Experten dann gut, wenn es klar, reduziert und handlungsorientiert ist. Nutzer brauchen verständliche Sprache, sichtbare Hilfestellungen und konkrete Empfehlungen statt technischer Details. Weniger Informationen, dafür mehr Kontext, Transparenz und Bezug zum Alltag schaffen Vertrauen und ermöglichen eigenständiges Handeln.
Inhalt
Hick’s Law: Je mehr Auswahlmöglichkeiten es gibt, desto länger dauert die Entscheidung.
